Your AI Agents Need an Org Chart
You start out with one agent. As you embrace the productivity boost you tolerate the small failures, after all, the working label has a nice shimmer effect on your terminal, and you start delegating more and more. Your agents start spawning subagents, but you can't sit still.
You want MORE AGENTS. So you start divvying up your backlog, proliferating worktrees, and suddenly you're juggling fourteen terminals and acting like a human clipboard while slowly losing your mind. What if you could orchestrate your agents?
The industry is in a mad rush to solve this, coming at it from wildly different angles. Turns out orchestration needs two things: agents that can delegate work down (and keep going deeper), and agents that can talk to each other.
Claude Code's Agent Teams got the communication part right, any agent can message any other. But delegation is capped at one level. Codex went the other direction with configurable depth, agents all the way down, but locked communication to parent-child only. Siblings are invisible to each other, everything routes through the boss. Perhaps the most sophisticated agent orchestrator, Gas Town, ships with free messaging and a deep role hierarchy — nearly 400,000 lines of code worth of orchestration. But the agent that delegates the work doesn't own what it delegated. It can't terminate a subtree, can't choose how to recover from a failure. Crash recovery, termination, completion are all handled by a separate monitoring stack.
In a company, when your direct report's project goes sideways, you handle it. You don't wait for some monitoring department to notice and restart them. You decide: reassign, retry, or cut your losses. An org chart encodes who is responsible for what, not who can talk to whom.
I've been building an orchestrator that separates the two.
What happens without authority
The research on multi-agent coordination is starting to pile up, and the failure modes keep pointing in the same direction: Authority gaps.
A benchmark called CooperBench tested what happens when peer coding agents work together as equals: no manager, no hierarchy, just a shared communication channel. Success rates were 30% lower on average than agents working alone. More agents made it worse, monotonically. Two agents succeeded 68.6% of the time. Three agents: 46.5%, four agents: 30.0%. The interesting part is that communication wasn't the bottleneck. Agents used the channel extensively, burning up to 20% of their action budget on messages, and it actually helped with merge conflicts (29.4% conflict rate vs. 51.5% without). But they couldn't converge on what to build. The paper sorts the gaps into three categories: agents acknowledge each other's plans then proceed as if nothing was said (expectation), agents claim work as done when it isn't (commitment), and agents fail to reach a shared answer at all (communication). The shared root cause is that no agent had the standing to decide what gets built, verify what got done, or call a halt when things went sideways. These were teams with Slack but no manager.
An analysis of over 1,600 execution traces across seven multi-agent frameworks found that nearly one in five failures are termination-related: agents that don't know when to stop (12.4%), or stop too early (6.2%). In org chart terms: nobody to say "this project is done" or "this project is cancelled."
When these gaps compound, the numbers get ugly. A Google Research study found that independent multi-agent systems amplify errors 17.2x compared to single-agent baselines. Centralized coordination, where one agent has authority to intervene and redirect, reduces that to 4.4x. (A caveat: every multi-agent variant degraded sequential reasoning tasks by 39-70%. This advantage is specific to parallel workstreams where decomposition and oversight matter most.)
You can see the gap in production too. Codex CLI has documented zombie processes: 1,319 orphaned agents and 37GB of leaked memory, spawned with no authority to reclaim them. Deep Agents shipped async subagents with a cascade cancellation bug where one failure cancels all parallel siblings, an example of authority flowing the wrong direction. These problems are showing up throughout the industry.
Intent flows down, outcomes flow up
Telecom engineers hit this problem decades before AI agents existed. When you're running a telephone switching system with thousands of concurrent processes, some of them will crash at odd hours with no one around to fix it. The solution, formalized in Erlang's supervision trees, was a structural principle: if process A creates process B, then A is responsible for B. Not as a design preference, as an architectural requirement. That responsibility relationship, replicated at every level, produces a tree. The core rule was the same one every org chart encodes: the entity that creates is responsible for what it created. OpenAI's Symphony inherited this directly, built on Elixir which runs on the same runtime as Erlang.
In a previous post I argued that create and destroy need infrastructure. The next question is what that infrastructure produces when you go deep — not one level of delegation, but three, five, ten.
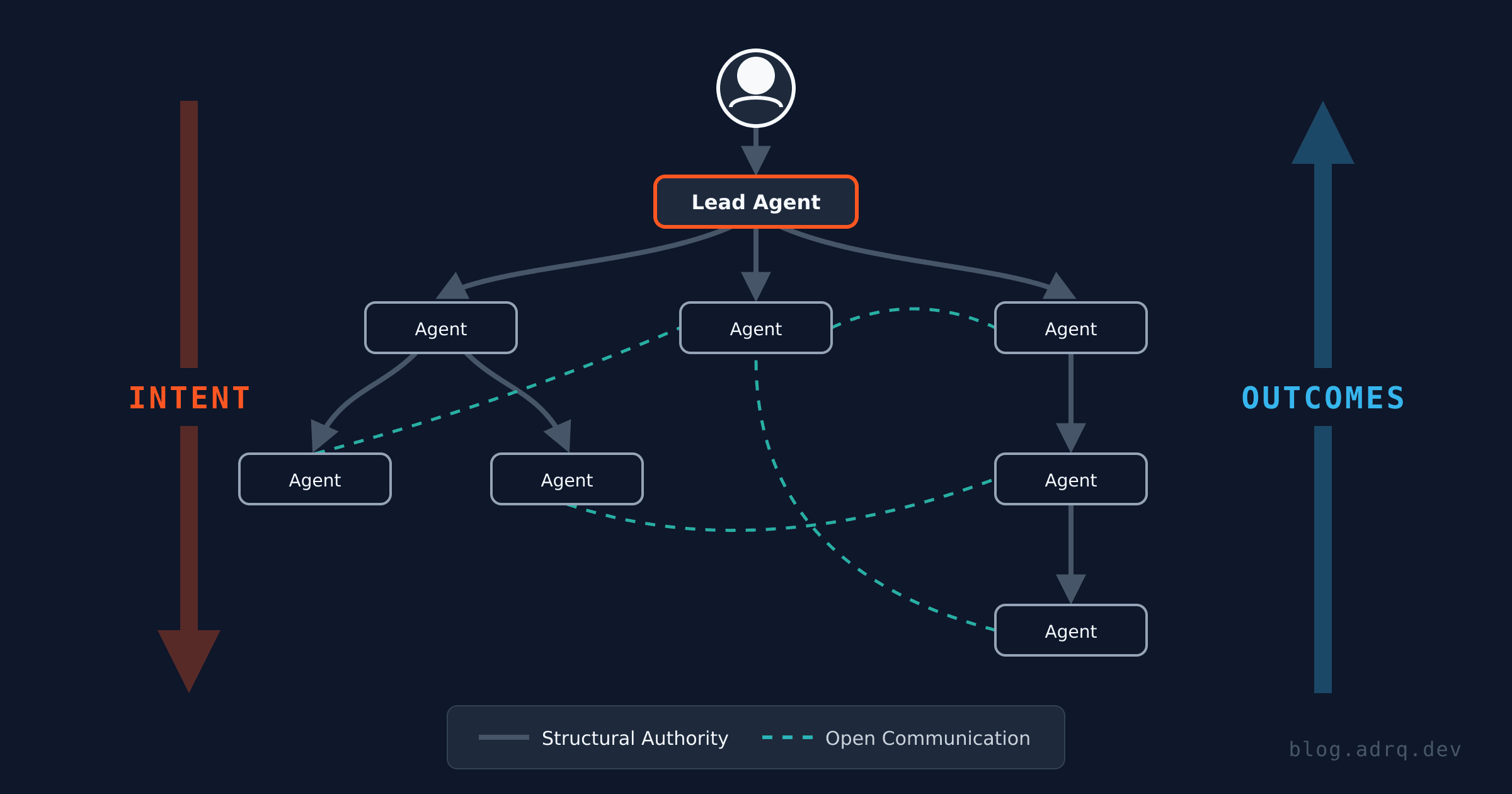
A useful way to think about this is information flow. In any hierarchical organization the intent tends to flow down and the outcomes flow up.
When a parent delegates, the child inherits the goal. When a parent terminates, that intent cascades through the entire subtree. Delegation and termination are both downward flows: one says "do this," the other says "stop." At the same time, outcomes flow up. When a child finishes or fails, the result surfaces to the parent. The parent absorbs it — retry, redelegate, or move on. A grandchild failure is the child's problem unless the child fails too. Each level of the tree filters the complexity below it, which is what makes deep delegation viable: whoever is at the root doesn't need to monitor every leaf. They manage one agent. That agent manages its own.
One important caveat is that while this authority tree should constrain who can terminate, recover, and verify lifecycle state, it should not constrain who can talk. Any agent should be able to message any other, like Slack in a company. You don't need your manager's permission to DM a colleague in another department. Block just articulated the same separation for their entire company: AI handles information routing, authority relationships persist.
Where are the current frameworks on this? Closer than you'd think. The spawn is there. Crash notifications exist. But cascade, recovery authority, and lifecycle reporting aren't in the delegation chain yet. Any framework with parent-child spawning is one architectural step from a full authority model. The gap is smaller than it looks.
What this looks like in practice
I've been building this separation into an orchestrator called AgentBeacon. The coordination surface an agent sees is two MCP tools:
fn delegate_schema() -> JsonValue {
json!({
"name": "delegate",
"title": "Delegate",
"description": "Assign work to a child agent. Returns immediately with a session_id.",
"inputSchema": {
"type": "object",
"properties": {
"agent": { "type": "string", "description": "Name of the agent to delegate to" },
"prompt": { "type": "string", "description": "Task description for the child agent" },
"cwd": { "type": "string", "description": "Working directory for child (defaults to parent's cwd)" }
},
"required": ["agent", "prompt"]
}
})
}
fn release_schema() -> JsonValue {
json!({
"name": "release",
"title": "Release",
"description": "Terminate a child session and free its resources. Works in any non-terminal state (including while the child is working). Also terminates any descendants.",
"inputSchema": {
"type": "object",
"properties": {
"session_id": { "type": "string", "description": "The session ID of the child to release (returned by delegate)" }
},
"required": ["session_id"]
}
})
}
Source: delegate_schema, release_schema
That's the whole coordination API. Everything else the infrastructure handles silently: cascade termination follows the delegation chain, crash recovery retries with a configurable budget or fails upward and notifies the parent, and when a child is terminated the system reports whether the exit was clean or interrupted. The agent delegates and releases. The system handles the rest.

The schemas above are the whole API. I run my own delegation workflows on it, and AgentBeacon is open source if you want to do the same. It's early — expect the rough edges that come with that — but the structural claim is testable today.
The interface boundary
This ownership structure changes more than reliability. It changes how humans interact with agent teams.
If each parent owns its children and absorbs their complexity, the human only needs to talk to the root. Not every agent, not every terminal. No more acting as a human clipboard between seven sessions. The tree becomes the interface boundary between human judgment and agent execution.
But that boundary creates a new problem. When agents can reliably execute deep hierarchies of work, the failure mode shifts. The bottleneck isn't crashes or zombies anymore, it's agents working on the wrong things. Without a structured way for agents to surface decisions upward, more agent capacity just means more wrong work, faster.
An org chart tells you who is responsible for whom. It doesn't tell you when to pick up the phone. That's the next question: what happens when you replace the chat window with a structured decision queue.